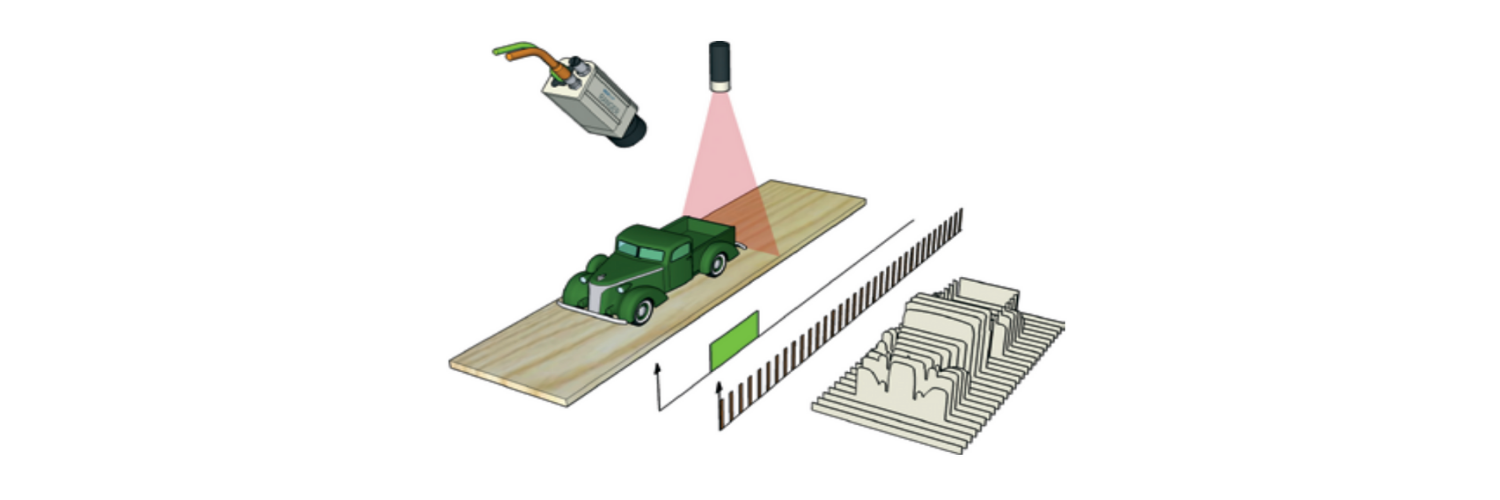

We recently had a project that included several unique and interesting technical problems to solve. One of those problems involved 3D scanning an object in order to create an in-memory representation of the surface of that object.
There were several factors that made this particular problem not exactly a walk in the park. The first challenge came from the 3D scanning hardware. The way the 3D scanner works is it projects a laser line across the field of view. As an object moves through the field of view (along the Y axis) it will block the laser at different heights which can then be translated into X,Z coordinates. The Y coordinate can then be calculated by the timing between consecutive scans.
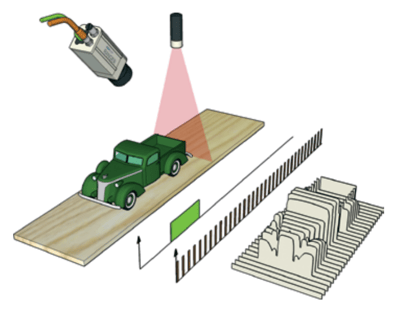
The scan process goes like this:
- The scanner is always on. That means we’re receiving a constant stream of 3D points.
- An object enters the field of view and blocks the laser. The camera sees this and we start receiving 3D points with a height calculated by where the laser reflects off the object.
- As the object continues through the laser the contours of the surface of the object are continually recorded.
- The object clears the laser and we begin receiving a stream of 3D points with a height of -1, meaning the camera does not see the laser deflecting off of anything.
From the above description you’ll note two problems that we have to deal with. One is filtering out points when nothing is being scanned. The second is determining when we’re done scanning the object.
There’s a third hardware-specific complication which is this 3D scanner batches up measurements before sending it to our code. Rather than receiving a single cross-sectional scan, we’ll receive a batch of 50 or more cross-sectional scans at a time. If we’re not careful with the Y values in those scans then each new batch of scans will start at Y=0 and it will appear as if the object overlaps itself.
These were interesting challenges to overcome both due to their technical intricacies and because we were doing asynchronous programming, but these challenges were not insurmountable. Through the rest of this post I’ll describe how we used observables and pure functions to greatly simplify this processing.
Creating a Mock 3D Scanner
In order to make these examples interactive I've created a mock 3D scanner that behaves exactly like the real thing and runs in the browser. This animation shows the output from this fake scanner.
.gif?width=390&name=ezgif.com-crop%20(2).gif)
Notice that it starts with a couple batches of scans of ground level points, then over the next three batches it displays the outline of a cup-shaped object. Also note that the Y values don’t shift with each subsequent batch of scans. If we were to take these point as they are the reconstructed object would overlap itself!
The code to produce this is relatively simple, but we won't be diving into those details. Here is the code if you're curious.
See the Pen Fake Scanner by Charlie Koster (@ckoster22) on CodePen.
Now that we have a mock 3D scanner let’s dive into how we used observables to translate and store these points in a more useful way.
Plotting valid points
Let’s start simple and address these challenges one by one. The first challenge to solve is to take the stream of points from the mock 3D scanner and filter out any points that do not have a positive Z value. We do this because any Z values (height values) that are at or below ground level are not part of the object being scanned.
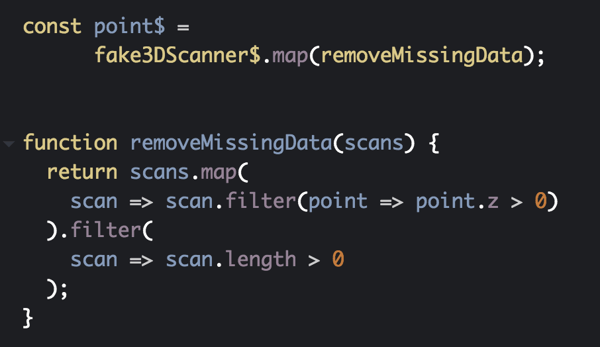
This code will take each batch of scans (remember that fake3DScanner$ will produce batches of cross-sectional scans of type Array<Array<Point3D>>) and for each scan it will filter out any points that do not have a positive Z value. Afterwards it does one final filter to remove any scans that no longer have any points.
We’re not quite done yet. It’s now possible for an entire batch to be empty if all of its scans had points filtered out. Ultimately we don’t want the downstream subscribe to trigger on empty scan batches so we filter those out as well.
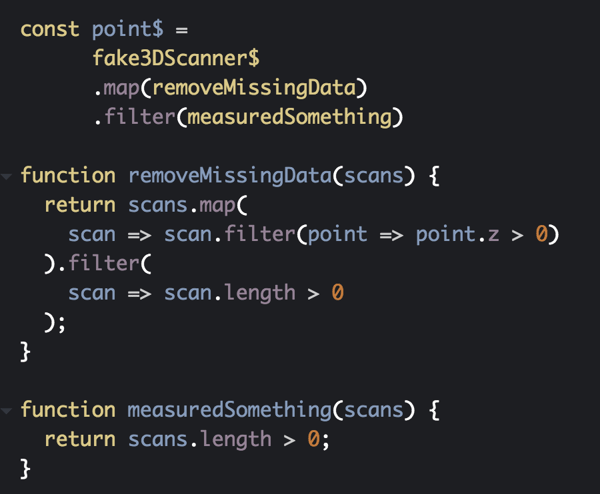
And that does the trick for filtering out invalid points! Any points that make it past these two filters are valid points.
It’s important to note a pattern we’ll see going forward. Observables are meant to be used with pure, stateless functions. Those are functions that take an input and return an output without producing any side-effects. By using stateless functions this will result in simpler and more testable code!
Stitching Batches Together
Now that we have valid 3D points representing a scanned object let’s take the batches the mock scanner is giving us and stitch all the scans together in order. In order to accomplish this we’re going to use an observable operator called buffer.
Buffer is an operator that will gather values from an observable into a collection and only let the collection pass through on a specific condition, such as when another observable emits any value. RxMables.com has a good visualization of this.
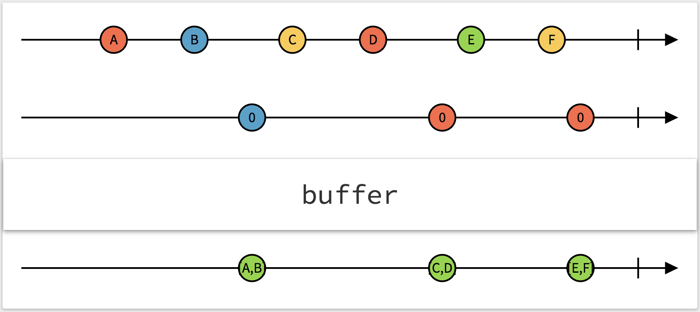
In the above illustration, whenever the second observable emits any value the values gathered on the first observable are sent through as an array.
For our use case we’re going to continue to collect scans until we’re done scanning the object. That begs the question. How do we know when we’re done scanning the object? We’re going to create another observable that is also taking in points from fake3DScanner$ and that observable will only emit when there is an entire batch of scans that doesn’t have any valid (Z value greater than 0) points. Once that observable emits, meaning once we have an entire batch of invalid points, that means we’re done scanning the object.
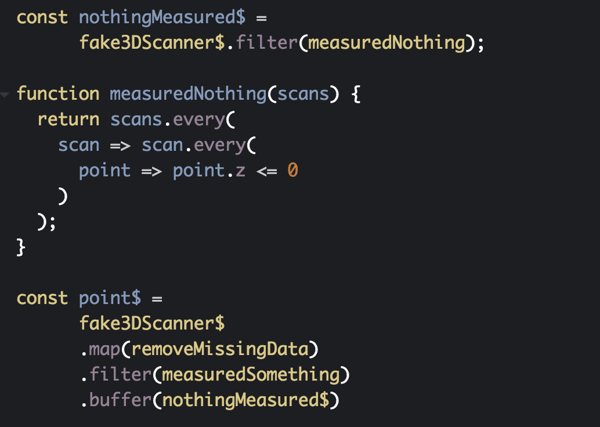
The nothingMeasured$ observable is passed as an argument to buffer and results in the image below.
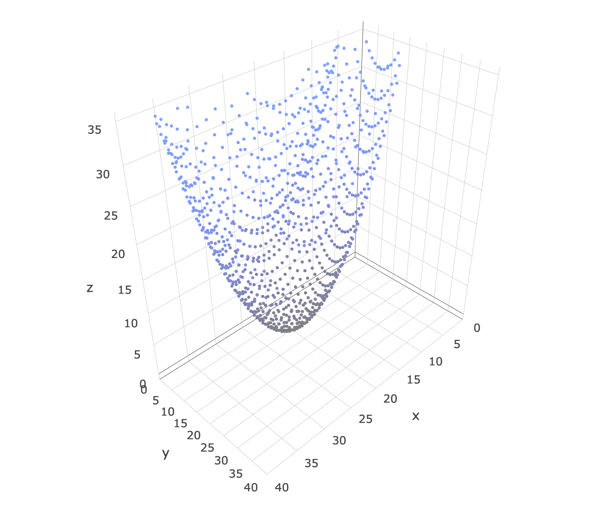
It’s difficult to tell from this image but what is shown above are three batches of scans on top of each other. This undesirable effect happens because each batch begins with points with Y values starting at 0.
We can solve this by taking the result of buffer , iterating through each batch, and taking the last Y value recorded in the previous batch and adding that to the Y values in all subsequent batches. In effect, this translates all cross-sectional scans along the Y-axis based on which batch they appear in.
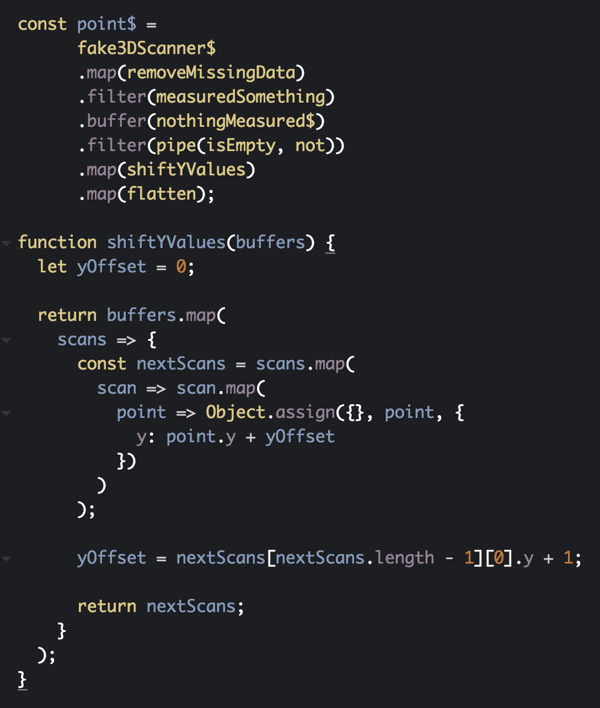
A quick reminder on the types and why there are several nested map calls in the shiftYValues function. The 3D scanner reads how an object intersects a laser line as Array<Point3D> but it also batches up those scans making it an Array<Array<Point3D>>. Because we’re using buffer to collect one or more batches the output of buffer is Array<Array<Array<Point3D>>>, a collection of batches. This is a little more clear when using languages with aliased types to create aliases such as Scan , ScanBatch , and Array<ScanBatch> .
Lastly, we append a final flatten to collapse the nested arrays, we send it to Plotly, and we’re left with a full reconstruction of the object that was scanned.
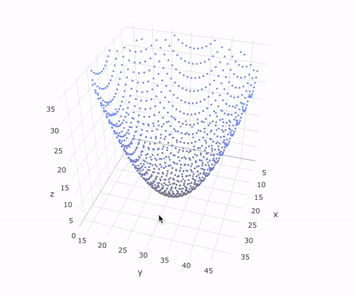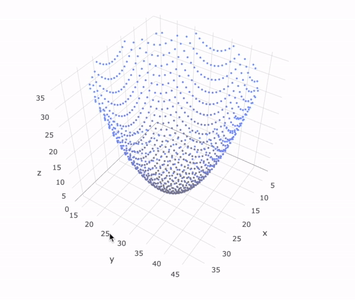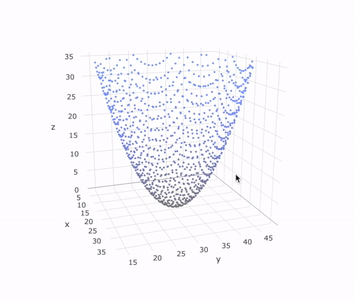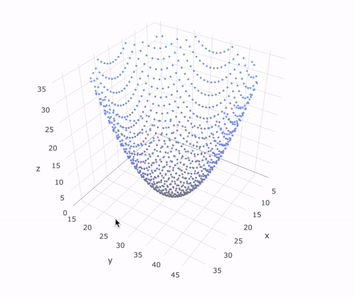
This analogous code example including the mock 3D scanner and Plotly visualization can be found in this interactive snippet.
See the Pen Full 3D Scanning Example by Charlie Koster (@ckoster22) on CodePen.
And here is the result of transforming the output from a real 3D scanner with objects we had laying around the office.
Observables are Great!
There are 8 lines of code that I want to highlight because of how truly powerful they are.
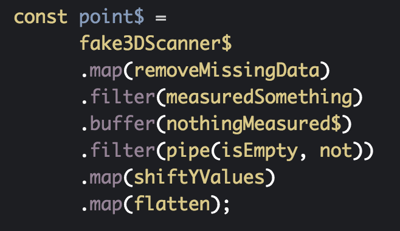
Ignoring all the small helper functions, this is the entire solution to our 3D reconstruction problem! This is great not only because of its simplicity but also because of how it compares to alternate solutions. What would this code look like if we didn't use observables? What would it look like if we passed around shared, mutable state? Observables not only made this problem easy but it also made it a joy to solve all the little puzzles and end up with a cool result!
